Data pipeline
Together with workflow, we can make the data flowing through recipes as pipeline.
With data pipeline, we can implement such scenario:
- one recipe is responsible for monitor any new item in the target web page, and the second recipe scrape new item incrementally
- to continue scraping from broken point caused by abmoral exit.
The logic behind data pipeline looks like waterfall:
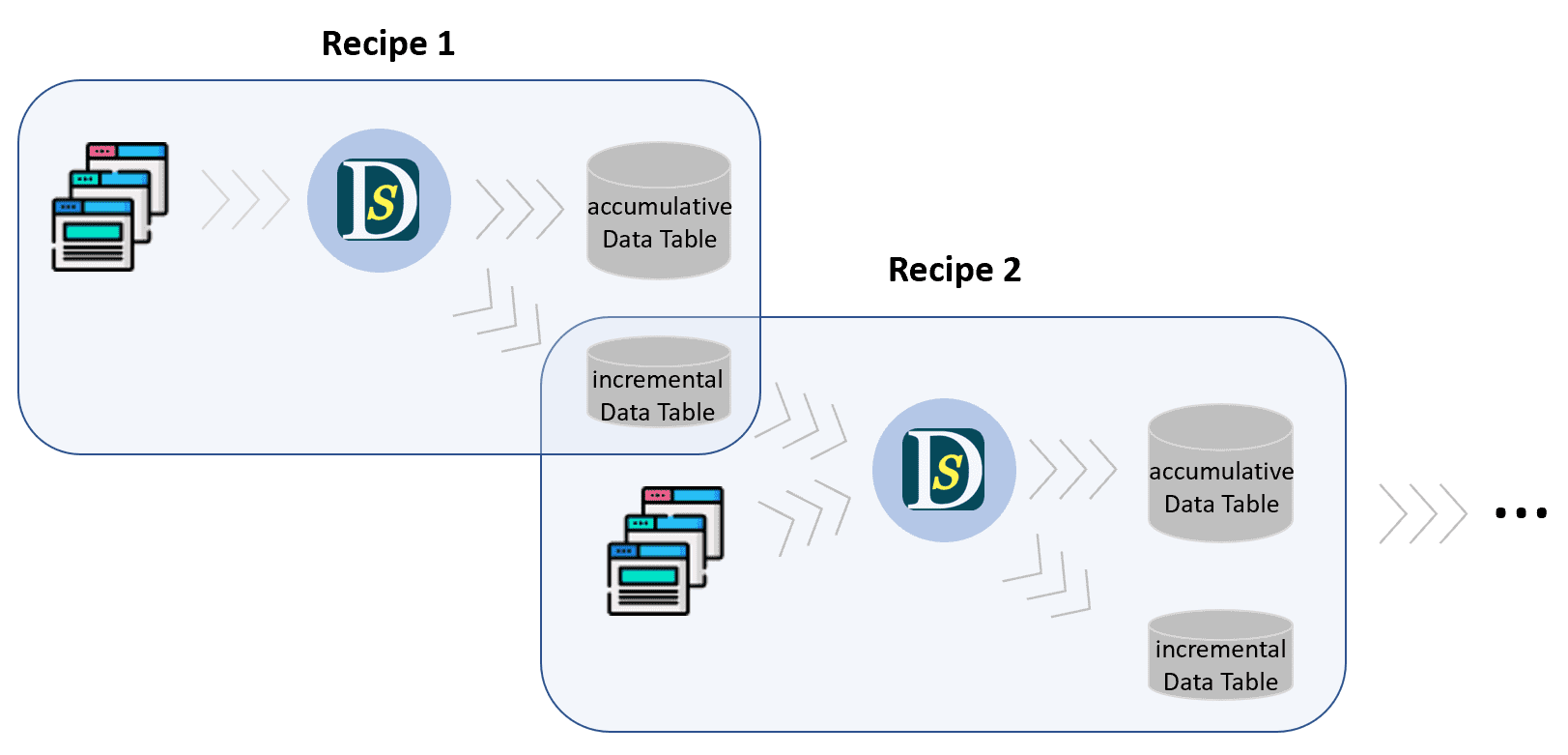
Here the first recipe scrapes data from website 1, store data to accumulative data table 1, and store new data to incremental data table 1. Then the second recipe reads data from incremental data table 1, and scrapes further data. Once one row in incremental data table 1 processed, recipe 2 will remove it from incremental data table 1. Thus only new added data via recipe 1 will be processed by recipe 2. The scraped data by recipe 2 can be saved to the second accumulative data table and the second incremental data table as well, and the pipeline can connect to another recipe for incremental data scraping.
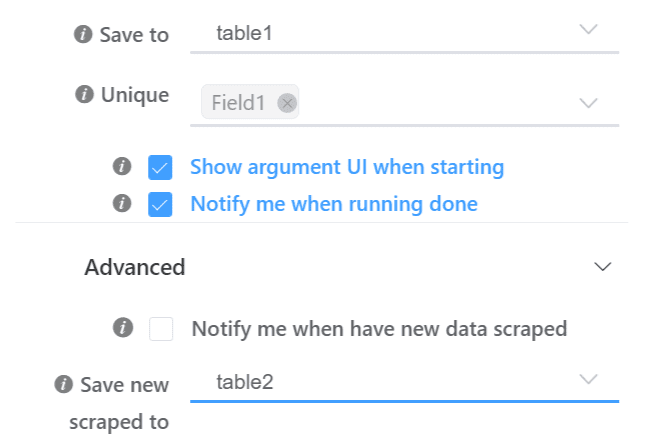
To implmenet pipeline is easy: (1) for the previous recipe, when saving recipe, declare 'Save to' table, set Unqiue keys, and declare 'Save new scraped to' table.
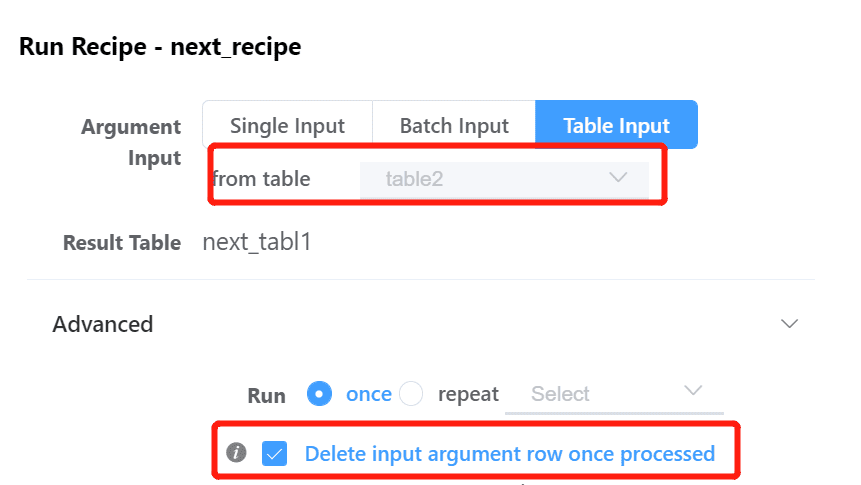
(2) for the next recipe, select the previous reicpes' incremental table as input, and when starting recipe, check 'Delete input argument row once processed'.