Incremental saving
Why need incremental data
THere are several data scraping and monitoring sceneario which need incremental data saving feature. For example,
- when scraping news list periodically, we would like scrape new published news each time.
- when monitoring a product's price, we would like saving pricing change only
- when deep scraping, we would like to filter out new URL at the entry level, and take deep scraping for new URLs only
To filter out new data, and process these new data using other recipes, we need to keep data in two tables:
- accumulative data table: to help check if the data to scrape is new
- incremental data table: to save new scraped data. All other recipes process the data here, and clear the data once processed.
How to configure incremental data saving When saving a recipe, after configuring 'Save to' data table and 'unique' fields, we can set an incremental data table via the 'Save new Scraped to' box on recipe saving dialog.
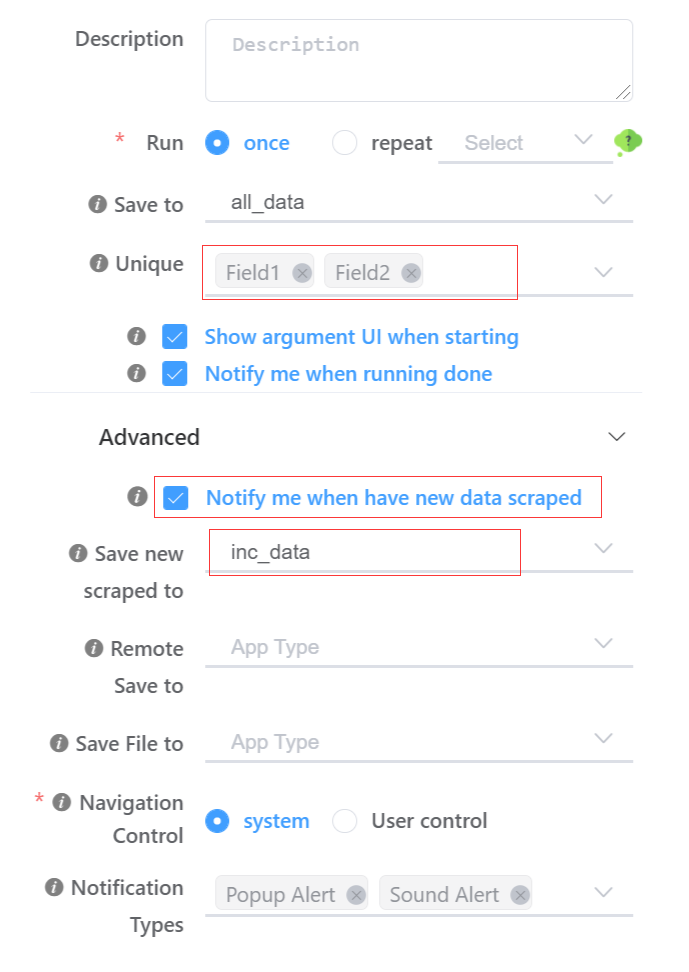
Here we will find that the incremental input box is accessible only when unqiue field(s) is not empty.
When incremental data table is sepcified, NDS will check scraped data to see if its unique fields' value is existing in the output data table. If no, then the row will be stored here.
Also you can check the 'Notify me when new data scraped'. So you will receive notification (type of message is configured on the bottom of the saving dialog) when new data scraped.
Now we have all accumulative data and incrmental data, to implement the incremental scraping described at the beginning of the page, please refer to Data pipeline