Multiple paginated list scraping
The previous section shows how to define recipe to scrape a detail page, where we locate one element for one field, and extract one attribute or content from the element as the value of the field. In the AI creator section, we also show how to scrape list page quickly. However, there are some special list page that AI creator cannot generate recipe suitable for our needs.
This section we will show how to locate and extract value from repeating elements on such list page via visual recipe creator.
Here we take Amazon for example: https://www.amazon.com/Smart-Watch-Accessories/b/ref=dp_bc_aui_C_3?ie=UTF8&node=7939902011
Step 1: open the page and decide the content to scrape.
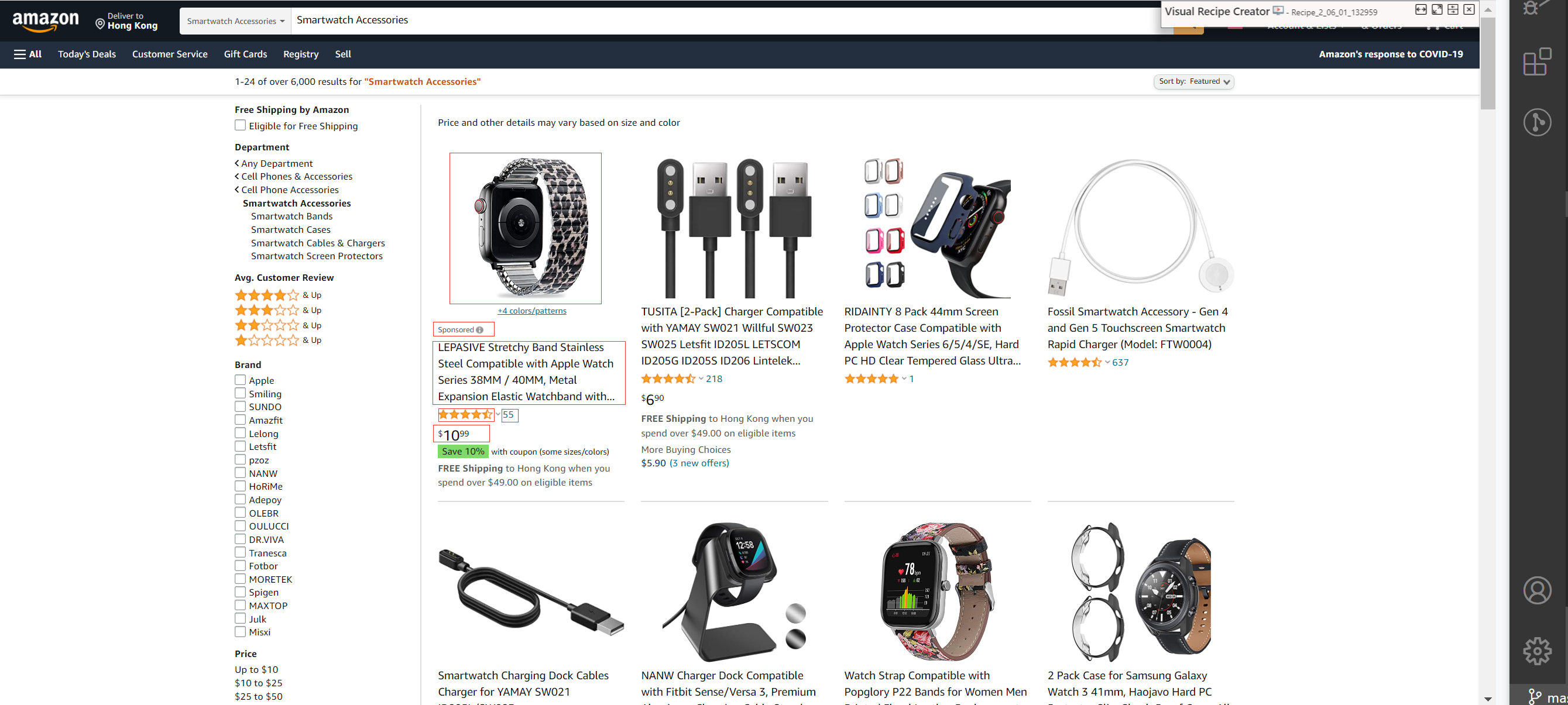
There is a list with multiple items, and each item has similar structure. On the bottom of the list, there is an obvious Next pagination button. We would like to scrape each item's attributes listed on the top 5 pages.
Step 2: start NDS, click 'Pro Scrape' on the popup window, and select the second template, "click 'Next' to scrape more pages".
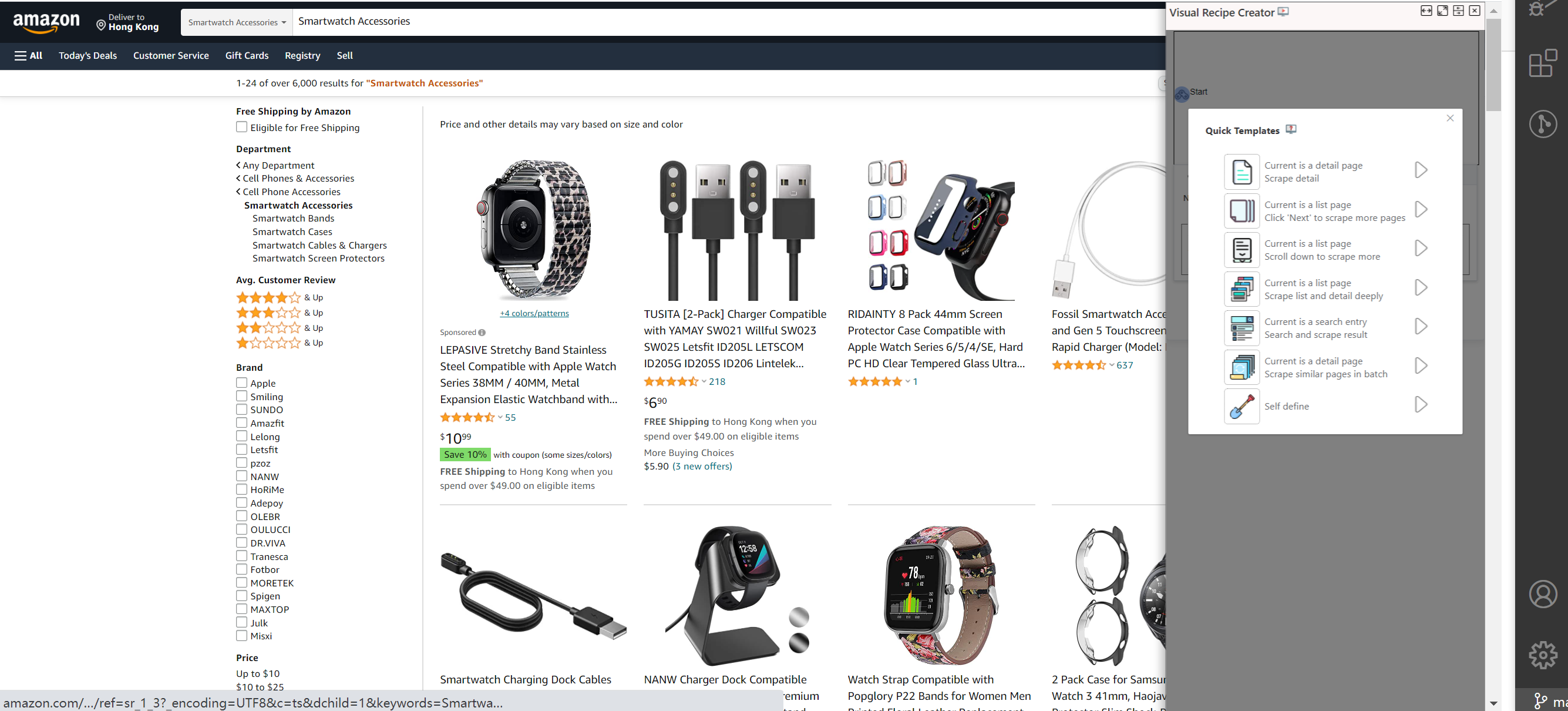
NDS will generate a recipe automatically with 2 nodes:
- Start : a Transit node with an openURL action in default.
- List1: a List node with an empty field(Field1) in default.
More details on List node please see What is node?
Step 3: for List node, we have to declare Block elements, and at least one field in the block.
All repeating fields declared here must be covered in the block. So we will select each item as a block.
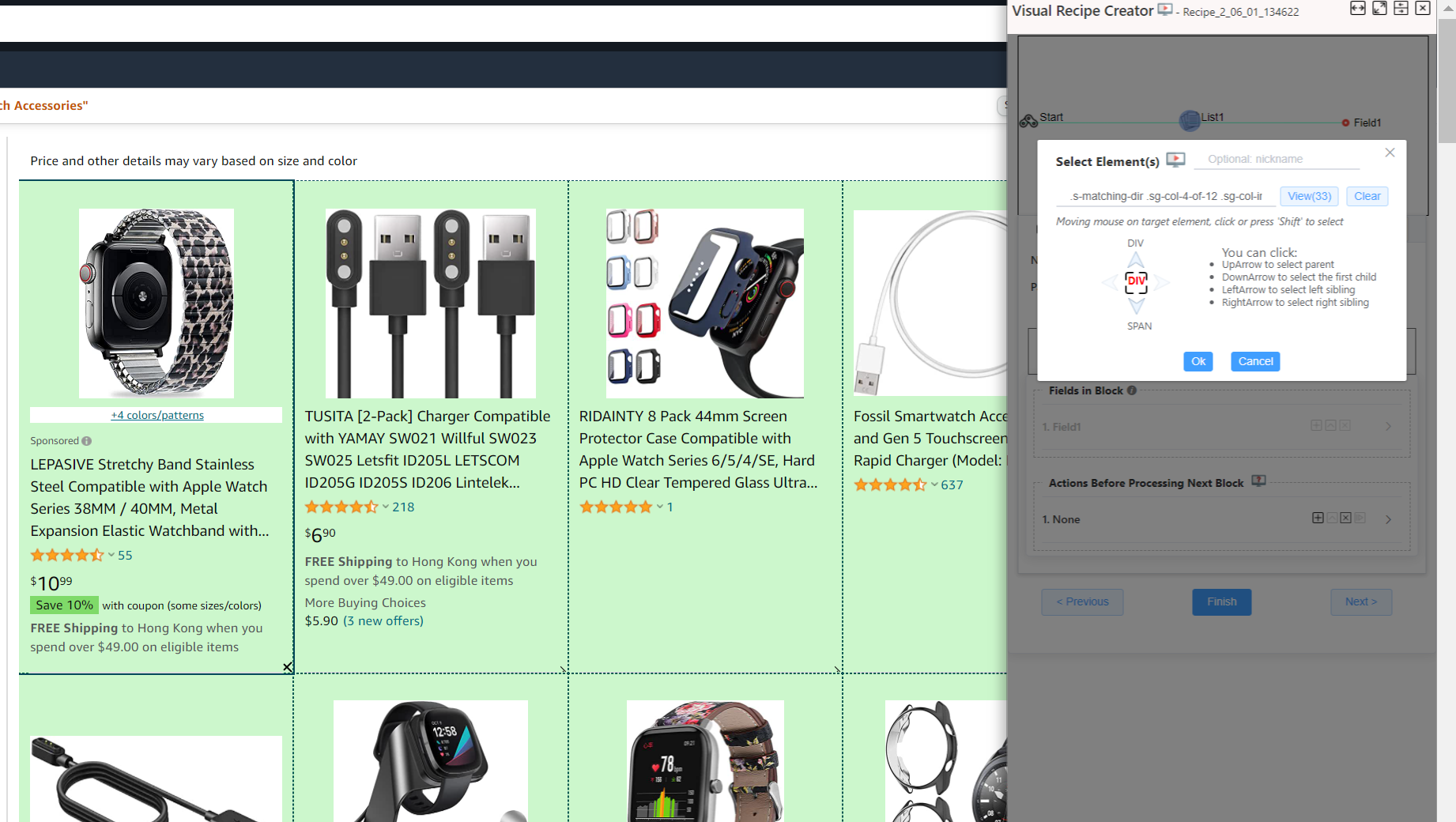
More detail on how to use Element Finder to select multiple elements, please see Element Finder guide
Here the Element Finder dialog shows that there are 33 blocks in the current page.
Step 4: use Element Finder to locate elements in the block for each field.
Once Field's Element Finder dialog is opened, all blocks are highlighted to tell that only elements in these blocks are selectable.
Now move mouse to the page and select one element in a block, NDS will try to figure out all similar elements in other blocks. If the similar elements in some blocks are not selected, you can move mouse to these elements and click them (or pressing Shift key). NDS will update all highlighted elements automatically once you select/unselect another element manually.
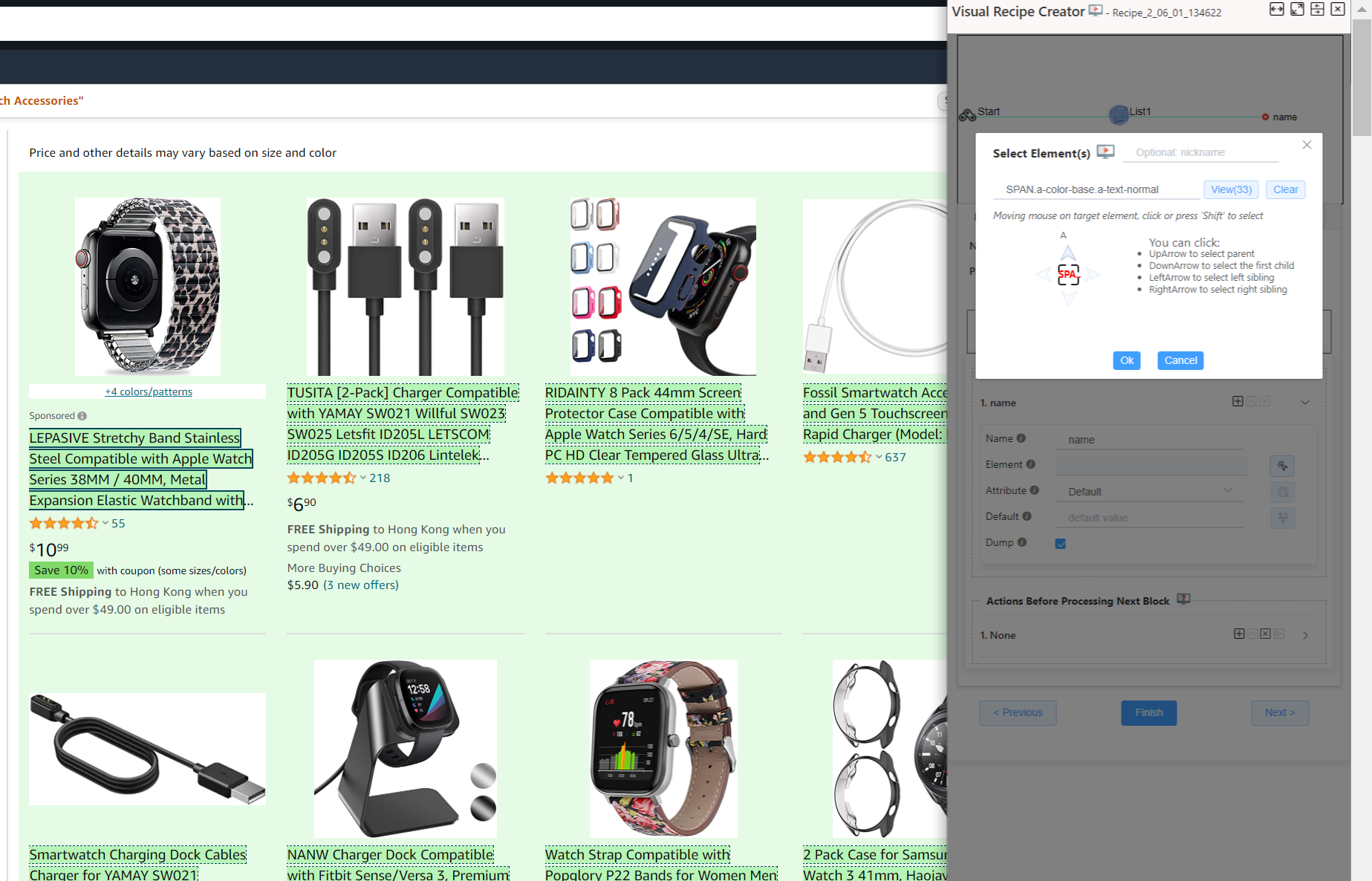
For each field, you can
- specify actions to impose on the target element before extraction (via clicking icon
 )
) - define attribute to extract from the target element. Except the built-in attributes, you can also type in specific attribute name directly
- download the image if the target element is an image and attribute to extract is image Src
- tranform the extracted value as you want (via clicking icon
 )
) - set a default value if you want. If no target element is declared for the field, then the default value will be return as the value of the field.
- declare if dump the field to output data table. If dump is not checked, the field's value will be extracted from the page, but will not be output to the data table.
After block and fields elements declared correctly, you can click the 'Preview' button ( ![]() ) to preview the extract result from the current page, and click it again to close the preview window.
) to preview the extract result from the current page, and click it again to close the preview window.
Step 5: click 'Next' wizard button on the bottom of the editor to go to 'Pages' tab
Here we define pagination to load more lists to scrape.
To make sure that pagination works fine on all following pages, there are four things we need to check:
- Do we need pagination?
- Is the pagiantion mode selected correctly
- Is the next button/link located correctly.
- Does the pagination work well on all following pages? i.e. the pagination works correctly from page 1 to page 2, from page 2 to page 3, so on and so forth.
If no further list to scrape, then we can check 'No Pagination' and go to next step directly.
To make pagination setting simple, NDS has 6 built-in pagination modes which can fit for most of pagination scenario, and with the help of Element Finder, there is no need to write any codes.
There is a simple guide to select the right pagination mode:
Does the page load new list via mouse click?
- Can we load new list via click one fixed button ?
- Does the new list replace the old one completely? If yes, select "Click 'Next' Button" mode
- Is the new list appended to the end of existing list? If yes, select "Click 'Load More' Button" mode
- Can we locate next page no via current one? If yes, select 'Click Page Number after Current One' mode
- Does the page list all page number? If yes, select 'Click Fixed Page Number One by One' mode
- Can we load new list via click one fixed button ?
Does the page load new list via mouse scroll?
- Does the page load new list via scroll the whole page? If yes, select 'Scroll Down' mode and let Scroll Target empty
- Does the page load new list via scroll mouse on specific zone? If Yes, select 'Scroll Down' mode and set Scroll Target element.
After selecting the right pagiantion mode, what we need is to locate the target element correctly. NDS's Element Finder will associate you to locate element(s) easily. More details please refer to Pagination in detail Element Finder guide
Up to now, we have declared the data to extract in a list page, and how to turn to next list page via automatic pagination. You can save the recipe. When NDS runs the recipe, it will open the start url automatically, and then extract multiple rows from the current page, where each block can be looked as a row, and each field can be looked as a cell in the row. Once all blocks in the current page processed, NDS will execute pagination (clicking or scrolling down) automatically to load another/additional list to process. When all list processed, NDS will end the scraping, and you can export data to local CSV from Data Center.