详情页采集
采集详情页是数据采集中很基础的一步。这儿我们以Yelp的GrandView餐厅为例进行采集: https://www.yelp.com/biz/the-grandview-restaurant-san-jose
第一步: 打开网址,并决定想要采集的内容.
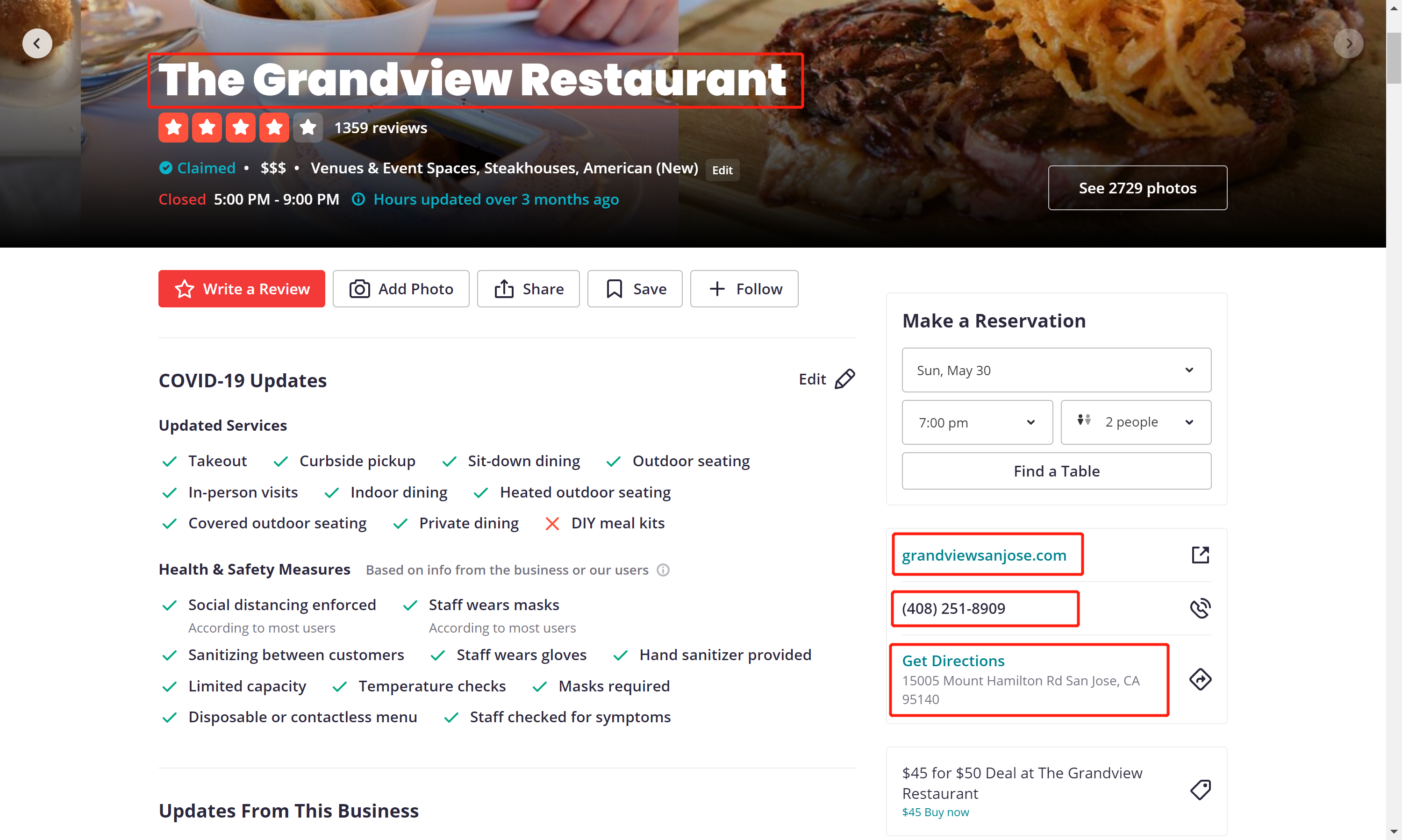
这儿我们希望能采集餐厅的名称、网址、电话和地址
第二部: 启动NDS,点击‘高级采集’,在弹窗中选择'采集单页信息'模板
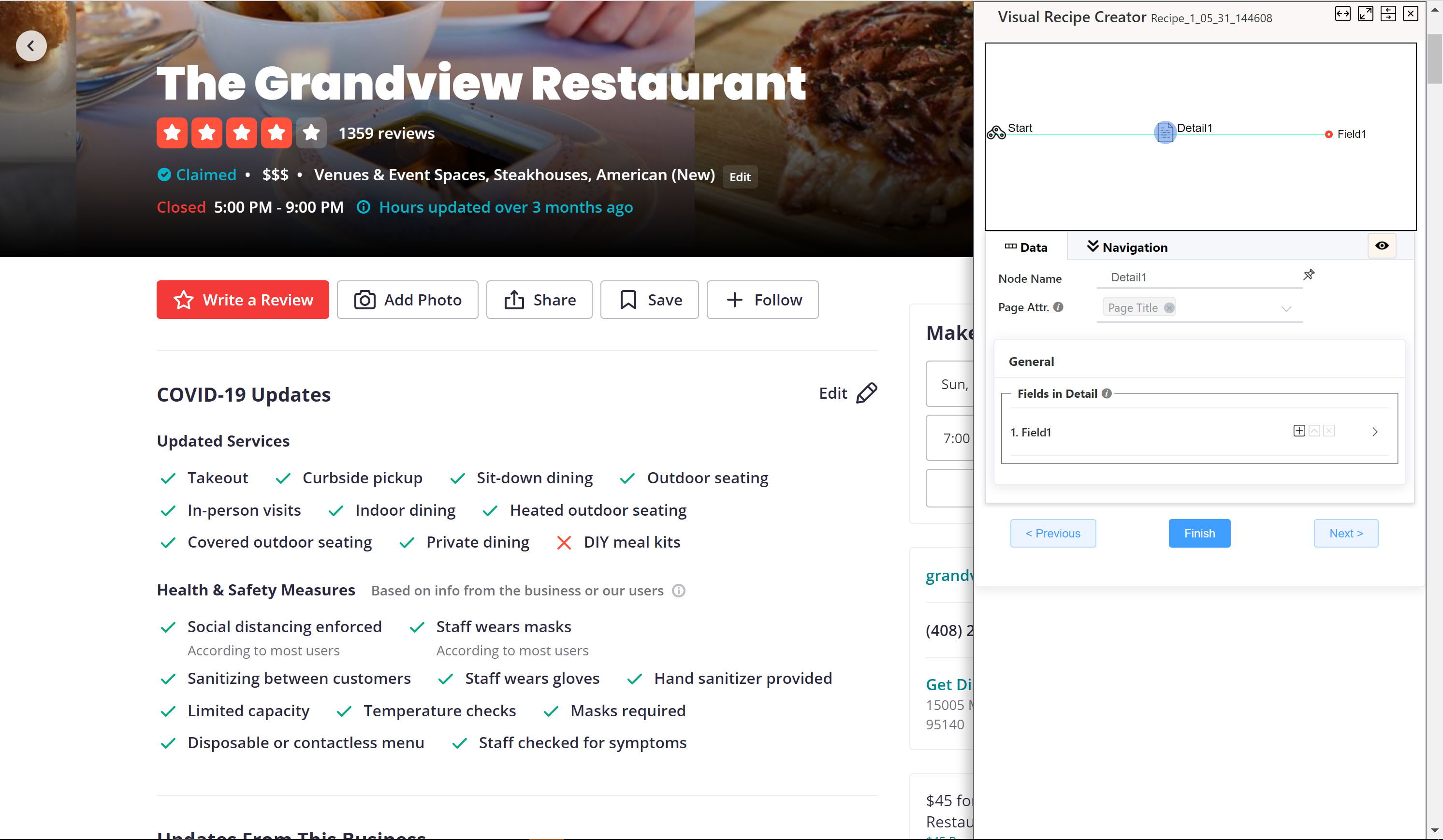
该模板会自动生成两个节点:
- 开始 : 一个关联节点, 默认带有‘打开网址’动作, 并且以当前网址为动作的参数.
- 详情1: 一个详情节点,带有一个空的字段.
第三步: 为每一个字段选择页面上对应的元素
更多关于如何使用元素选择器,请参见元素查找器详解
第四步: 决定是否需要深度采集
这儿我们可以点击某个字段来打开新的页面,并在新的页面上继续采集;或者我们可以直接进入下一节点, 在当前页面上执行下一节点的采集任务
如果决定深入采集,则点击底部的‘下一步’按钮, NDS会提示您创建新的节点。更多关于导航的信息, 请参见 导航详解
第五步: 点击‘完成’按钮,保存规则。
如果有必须的配置缺失,则NDS会弹窗提示您,请按照提示找到对应的节点-标签页做修改。
例如:
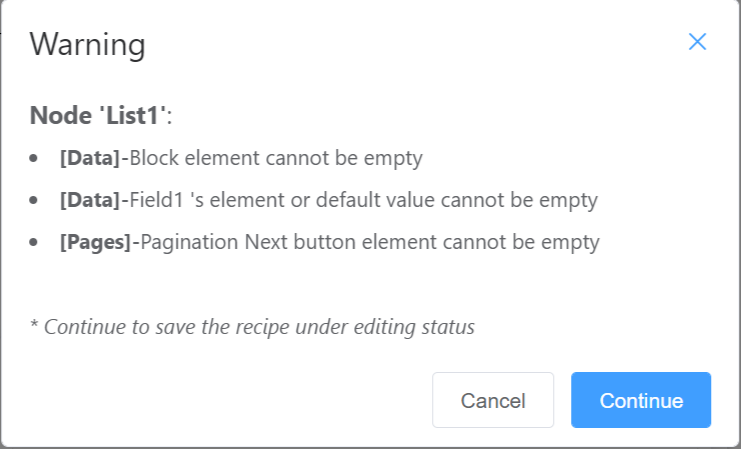
其中提示在节点'List1':
- Data标签页中, block元素确实; Field1's 元素 and 默认值 两者至少需要一个
- Pages标签页中, 选定了点击翻页按钮,但是按钮没有指定
如果点击‘继续’,则规则将保存为草稿。草稿规则都以( ![]() ) 图标开始。
) 图标开始。